
Meet GoPlant
Your Mobile Operator Rounds Solution
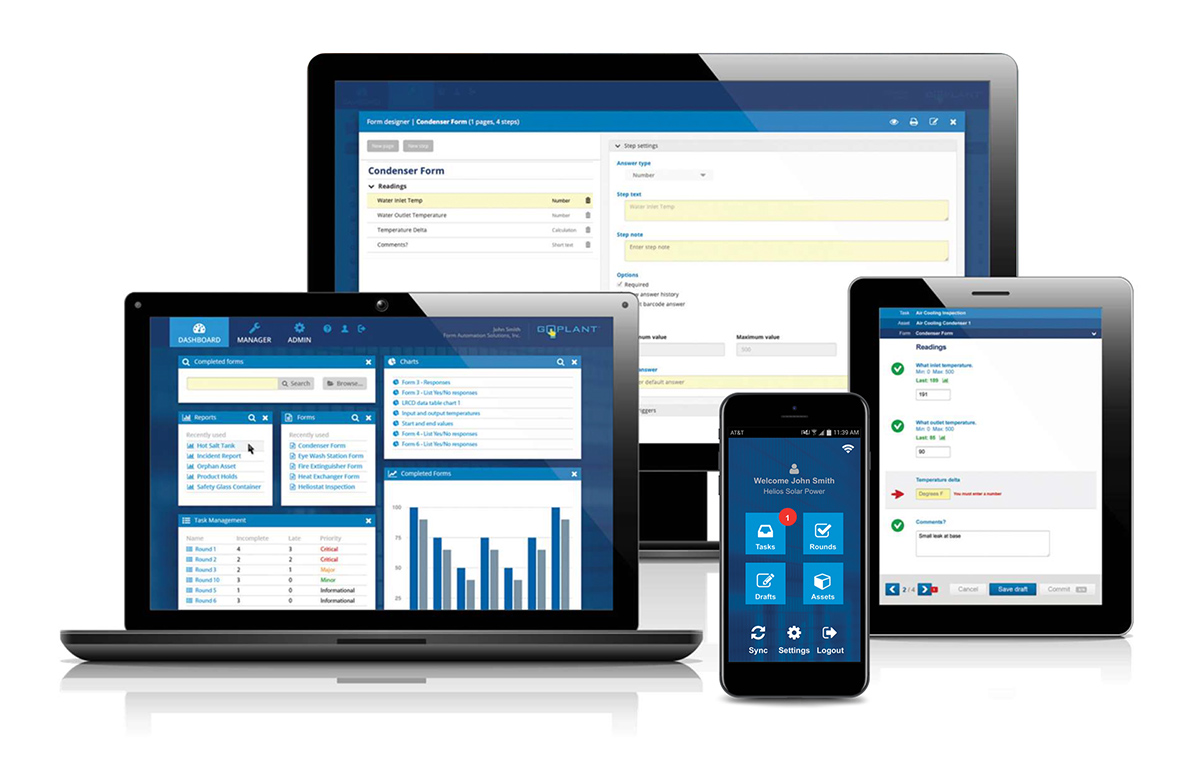
Data-Driven Actions on a Scalable Platform
GoPlant is a scalable mobile operator rounds solution for task management, data collection and decision support. It eliminates manual report generation, enforces timely and complete data collection and provides step-by-step instructions to field workers to ensure that best practices are followed when problems are encountered.

GoPlant provides more data collection capabilities and consistent corrective action instruction in real time. When further effort is required, GoPlant issues escalation alerts to the proper teams to ensure the plant doesn’t have unscheduled downtime, suffer safety incidents or fall out of regulatory compliance.

GoPlant keeps up-to-date plant rounds and checklists organized and available at the operator’s fingertips. It also manages the schedule for data collection and observational tasks, reminding the operator as work becomes due. Task compliance reports are automatically generated to ensure accountability.

When unusual conditions are encountered in the field, GoPlant can assist in troubleshooting the problem and leads the operator through corrective action, when possible. Alerts can be sent up the chain of command to make sure issues don’t fall between the cracks.

Round summary, round detail and exception reports are just a sample of the standard reports in GoPlant, or you can create custom reports from 70+ templates. GoPlant ensures data is collected the same way every time, providing the operator with a consistent workflow to address issues they uncover.

Regulations and compliance standards are constantly changing. GoPlant will help organize and manage many types of safety, regulatory and environmental compliance programs, state legislative and insurance audits plus your internal compliance programs.

How It Works
Despite today’s impressive advances in instrumentation and automation, there’s still no substitute for regular human observation and hands-on corrective action. Because of their proximity to equipment, operators are usually the first to detect even the slightest changes in process conditions and machinery health.
Overall, GoPlant minimizes operational risk, lowers operating costs, improves safety and reliability and empowers workers to perform simple daily routines that support plant performance.
Enhance your operator rounds with GoPlant, a productivity-boosting mobile solution for task management, data collection and decision support.


